
本文介绍了如何使用ollama和docker部署deepseek模型。作者首先安装了docker和ollama,然后进入容器安装模型。在模型下载过程中,作者发现下载速度会逐渐变慢,于是通过编写脚本实现模型的高速下载。最终,作者成功运行了deepseek模型,并分享了运行效果。
此内容根据文章生成,不代表个人观点,仅用于文章内容的解释与总结
随着deepseek的大火,dp模型的开源导致越来越多的人投身AI,并进行本地化部署。事实上,之前我在学习docker时,曾尝试过基于docker部署本地化模型,利用ollama部署的阿里云模型qwen2:0.5b。具体部署过程可以参考我csdn上的博文:
玩转Docker:Lsky pro图床+私有化部署大模型(Ollama+Openwebui)
所以,根据以往的经验,如今来尝试deepseek模型的部署,应该也算不上什么难事。deepseek-r1的模型类型及部署要求如下:
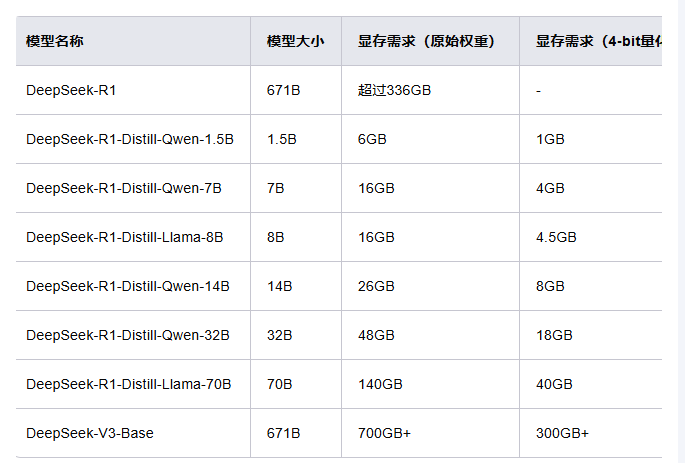
R1满血版不敢想,但是太低的也不想考虑,起码部署个中等的吧,所以我首先考虑的是14b和32b。当然,这里的部署并不是说就是拿来用,主要是想体验下部署的过程,更多的是学习和了解。因此最近一直在留意有没有高内存的测试服务器。但是大多数都是8g以下的一个月几百上千。我只是想学习学习~不是真的要买啊。就没有免费试用或者便宜点的吗?
终于,机缘巧合下出现了契机。一元/天试用尝鲜版:

一天就一天吧,都这个配置了,要啥自行车啊。开搞!
1.安装docker及ollama
docker安装不用说了,主要就是基于docker安装ollama。
###docker下载ollama部署
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama --restart always ollama/ollama
##使用docker部署webUi页面,${inner_ip}替换为你的本地ip
docker run -d -p 3000:8080 -e
OLLAMA_BASE_URL=http://${inner_ip}:11434 -v open-webui:/app/backend/data --name
open-webui --restart always ghcr.nju.edu.cn/open-webui/open-webui:main在下载ollama可能会出现找不到镜像的情况,所以这里需要设置apt镜像,进入daemon.json文件配置镜像源,没有就创建。
vi /etc/docker/daemon.json
然后使用 systemctl restart docker命令重启Docker即可。然后使用docker info命令查看镜像仓库信息,如果出现你所配置的源地址,就说明成功了。
{
"registry-mirrors": [
"https://2cc2e98fbd5b4ca482a3faf3884425e2.mirror.swr.myhuaweicloud.com",
"https://docker.anyhub.us.kg",
"https://dockerhub.jobcher.com",
"https://dockerhub.icu"
]
}2.进入容器安装模型
在安装ollama之后就可以通过 http:your_ip:3000 进行访问了。但是这个时候还没有模型。所以需要给ollama安装你想要的模型
终端输入:docker exec -it <container-id> /bin/bash
container-id为ollama容器id,进入到容器内。后面可输入以下命令进行对应操作:
### 安装模型 ollama pull qwen2:0.5b ### 启动模型 ollama run qwen2:0.5b ### 列出所有安装的模型 ollama list ### 移除模型,NAME模型名称 ollama rm <NAME>
因为这里我们是想利用ollama来部署deepseek。所以可选模型就是:deepseek-r1:32b deepseek-r1:14b deepseek-r1:8b 等等
3.模型下载|中断|网速慢|问题解决
在下载模型过程中,会发现一个有意思的事,刚开始会比较快,后面随着时间的流逝下载速度会越来愈慢。
我刚开始是选择ollama push deepseek-r1:32b ,眼睁睁的看着它从开始的下载完要3小时到8小时。我放弃了...
然后是 ollama push deepseek-r1:14b 2小时到4小时,果断放弃
最后是 ollama push deepseek-r1:8b 2小时左右波动
后面经过查询,发现一个有意思的解决办法。
1.通过Ctrl+C组合键中断下载之后,再次运行ollama run命令,发现刚开始速度快,后面慢下来了。
2.重复使用该操作,实现模型高速下载,通过脚本自动循环实现该操作。
于是,有意思的事情开始了~~

linux循环下载脚本bash:
#!/bin/bash while true; do # 检查模型是否已下载完成 modelExists=$(ollama list | grep "deepseek-r1:8b") if [ -n "$modelExists" ]; then echo "模型已下载完成!" break fi # 启动ollama进程并记录 echo "开始下载模型..." ollama run deepseek-r1:8b & # 在后台启动进程 processId=$! # 获取最近启动的后台进程的PID # 等待60秒 sleep 60 # 尝试终止进程 if kill -0 $processId 2>/dev/null; then kill -9 $processId # 强制终止进程 echo "已中断本次下载,准备重新尝试..." else echo "进程已结束,无需中断" fi done
window循环下载脚本:
# 引入 Windows Forms 命名空间
Add-Type -AssemblyName Microsoft.VisualBasic
Add-Type -AssemblyName System.Windows.Forms
# 弹出输入框,获取用户输入的模型名称
$modelName = [Microsoft.VisualBasic.Interaction]::InputBox(
"请输入要下载的模型名称(例如:deepseek-r1:32b):",
"模型名称输入",
"deepseek-r1:32b" # 默认值
)
if ([string]::IsNullOrWhiteSpace($modelName)) {
Write-Host "未输入有效的模型名称,脚本已退出。"
exit
}
while ($true) {
# 检查模型是否已下载完成
$modelExists = ollama list | Select-String $modelName
if ($modelExists) {
Write-Host "模型已下载完成!"
break
}
# 启动ollama进程并记录
Write-Host "开始下载模型..."
$process = Start-Process -FilePath "ollama" -ArgumentList "run", $modelName -PassThru -NoNewWindow
# 等待60秒
Start-Sleep -Seconds 60
# 尝试终止进程
try {
Stop-Process -Id $process.Id -Force -ErrorAction Stop
Write-Host "已中断本次下载,准备重新尝试..."
}
catch {
Write-Host "进程已结束,无需中断。"
}
}有点不当人,但出乎意料的好用。8b的在运行时发现cpu都快拉满了,看来还是我想简单的。14b及以上的应该需要更高的配置才行。不过最后也是成功的运行出来了。效果如下:

我想本地部署的。但是我电脑配置又不行|´・ω・)ノ
感觉有需要的企业部署一个还行,个人部署还是对硬件要求太高。
这配置要求,300 g。
部署完也不知道啥样的
有300G干啥不好,配这玩意做啥。免费的都够用了
一次部署一直爽 可部署好折腾好以后又要吃灰一阵子了 然后看了其他好玩的项目 又跑去研究其他的了
我这是单纯练手的,没必要用自部的,网上开源的那么多
我并没有用 AI 做很多活,可能更多就是代替传统搜索,直接问 ai,看它的总结。
恰好今天在 B 站看见一个说咱们国内很多人用ollama 搭建 DeepSeek,都不注重网络安全,甚至还用的 http 明文传数据。还有些网站专门找这种有明显漏洞的ollama 服务。
这个要注意啊!
这个我倒没关注,反正是测试用的,无所谓
赞,当时发现了ctrl+c中断重新下载可以速度回来,但是没有想到脚本来弄0.0
办法总比困难多